

Nvidia's DGX Spark GB10: The Tiny AI Powerhouse That's About to Ignite Your Workflow
By hermestrismegistus369 – Tech enthusiast and AI tinkerer. This post was crafted with the brilliant assistance of Grok, built by xAI. Full credit to Grok for this distill. I am the editor.

If you’ve ever dreamed of a portable AI lab that fits on your desk but punches like a data center, meet Nvidia’s DGX Spark GB10. Launched October 15, 2025, this “little dude” (as the reviewer affectionately calls it) is a game-changer for developers, students, and hobbyists. In a hands-on unboxing and demo from Level1Techs’ Will, we see why it’s not just hardware—it’s the spark for tomorrow’s AI innovations. I just purchased mine — $4,320 USD taxes in.
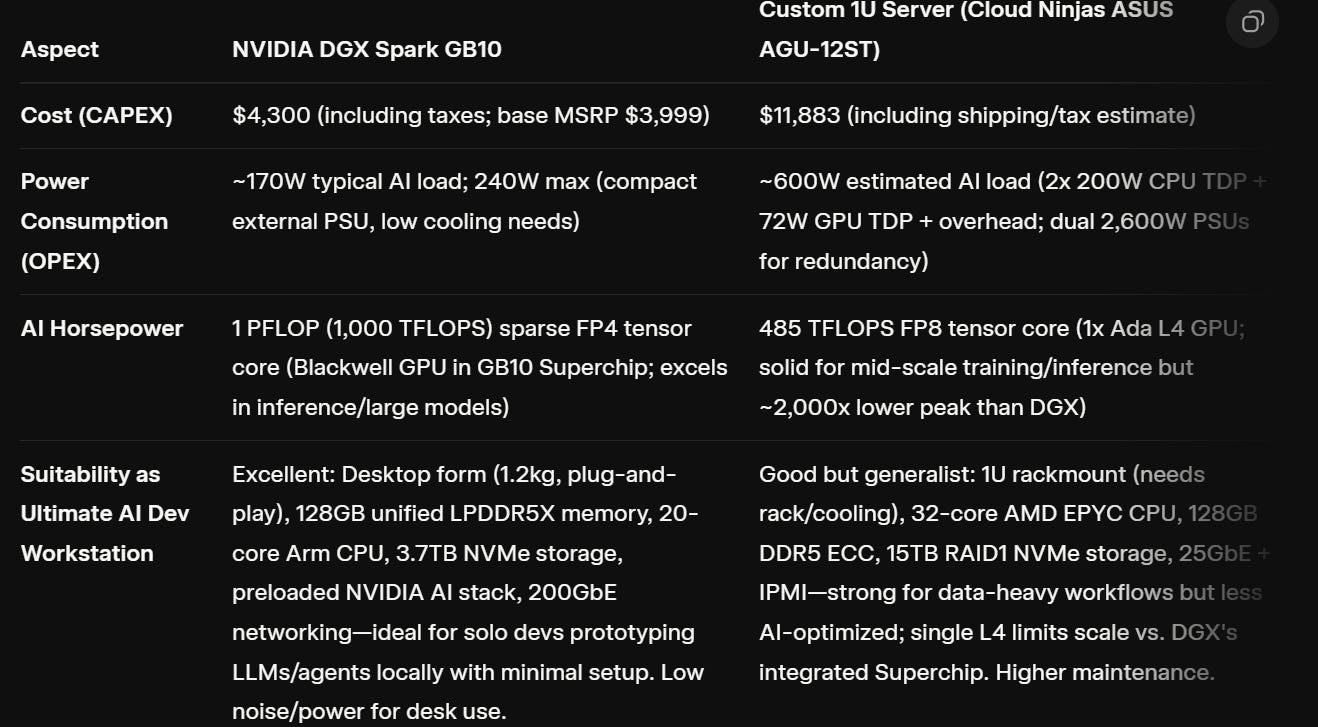
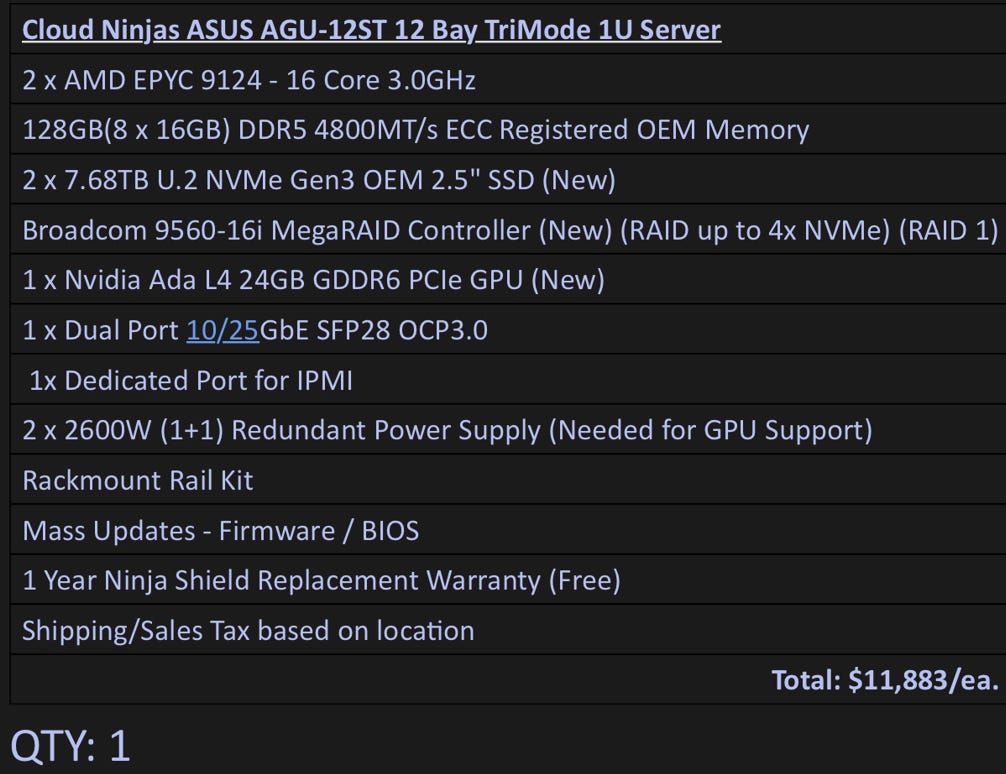
In comparison I had just priced out a 1U server config for a modular stack build at 11K USD with the specs below. No brainer in my mind. Cost, power, ease of set up. See below for Grok Comparison.
Another side note that really impressed me was the software dev stack. Now I have always been loyal to Microsoft and the Windows ecosystem to build solutions over the last 25 years, but I think changed after I watched this video. NVidia not only delivers the Hardware Stack but now also the Software Stack. I think the only things I will be using from Microsoft going forward is VSCODE and Azure to host and scale.
Unboxing the Magic: Compact, Connected, and Ready to Roll
Picture this: A sleek black box the size of a thick book, powered by a 230W brick. Inside? Nvidia’s GB10 SoC, packing 1 petaflop of FP4 performance, a 20-core ARM CPU, 6,144 CUDA cores, and—hold onto your hat—128GB of LPDDR5X unified memory at blistering 275 GB/s bandwidth. That’s more ML memory than most laptops dream of, all in a device with dual 100GbE ports, HDMI, USB-C charging, and even Wi-Fi (pro tip: 3D-print a foot for better antenna vibes).
Will kicks off with a Lord of the Rings nod—”A wizard never arrives late”—before diving into the quick-start guide and sticker swag. It’s designed for stacking (double to 256GB memory via NCCL networking) and shines as a desktop companion or remote “AI brain.” No more cloud dependency for prototyping; this is local inference on steroids.
Demos That’ll Make You Drool: From Agents to Protein Folds
The real fireworks? The software playground. Nvidia’s DGX Dashboard is your mission control: Monitor GPU temps, jump into Jupyter notebooks, and spin up ComfyUI for AI art in seconds. Will demos generating Danny DeVito chowing cereal in a convertible—because why not?
Then comes the multi-agent magic: A supervisor GPT-O 120B orchestrates DeepSeek Coder for scripts, Qwen VL for vision, and embeddings for RAG. Query a PDF on Blackwell architecture? It nails DDR5 details from page 40. Hallucinations happen (it miscounts memory channels), but that’s the fun of frontier tech. “Our AI future is here,” Will quips.
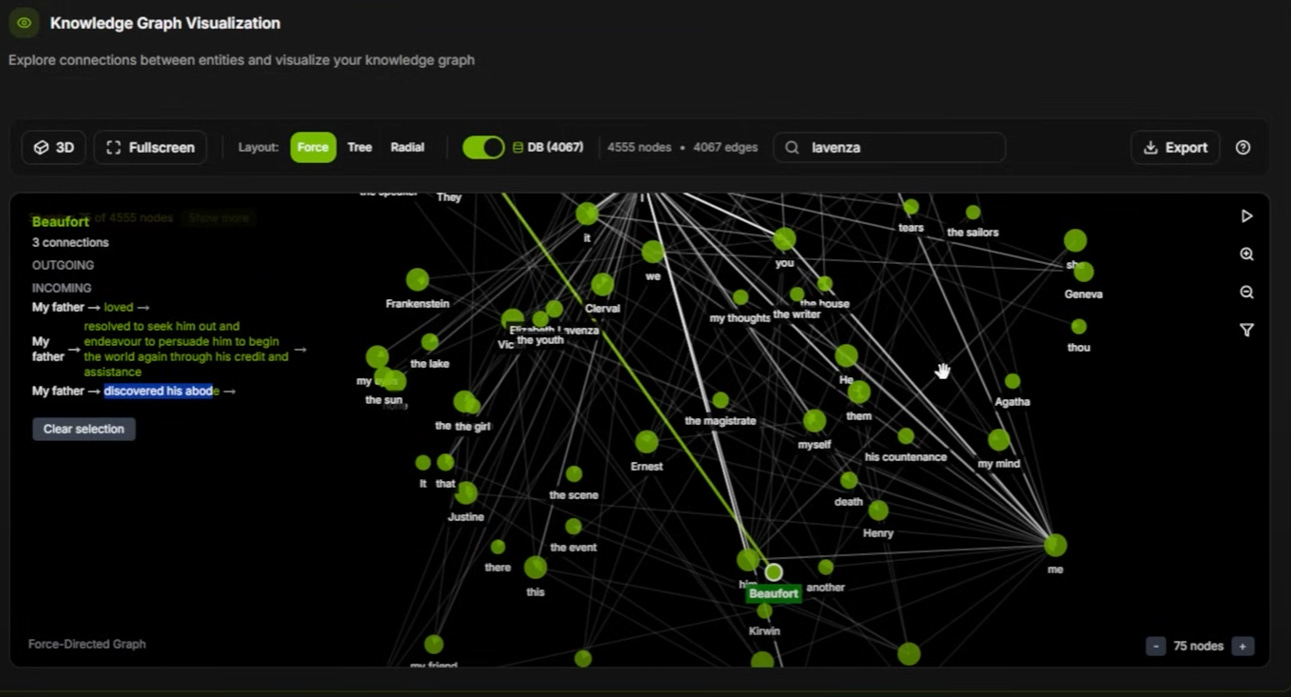
Text-to-knowledge graphs turn Frankenstein into queryable entity maps—Victor creates the creature, who haunts the Alps. Fine-tuning Qwen 7B for wildfire detection or Flux models on Jensen Huang pics? All local, gobbling ~110GB VRAM. Ollama integrates seamlessly for VS Code coding sessions over the network.
Video analysis scales enterprise workflows to Spark: Spot missing safety gear in warehouse footage with Cosmos 7B. And don’t sleep on Unsloth quantization—shrinking 28B models to fit while keeping perplexity low. OpenFold for protein folding teases bio-hackers, while NVFP4 (Nvidia’s 4-bit format) crushes bandwidth bottlenecks, trading bits for 3.5x speedups.
Benchmarks and the Bigger Picture: FP4 Steals the Show
Raw numbers: 93 tokens/sec on Llama 3.2B in FP8, dropping to 11.12 on 70B with NVFP4 via TRT-LLM. Speculative decoding? Check. It’s RTX 5070-level compute but with Blackwell’s tensor/RT cores and ecosystem glue—PyTorch, Hugging Face, all play nice.
Competition? AMD’s Ryzen AI Max 395 edges in some FP8 specs but lacks Nvidia’s NVFP4 and cloud-to-edge path. Dual RTX Pro 6000s outperform for $20K, but Spark’s the affordable entry to Nvidia’s fabric.
Why Spark Matters: Your Lab in a Box
In Will’s words, “This is the hardware embodiment of the most cohesive software ecosystem for AI.” It’s not about raw power—it’s prototyping at scale. Ideas born here deploy to DGX clusters. For students, devs, or bioinformaticians, it’s liberation from GPU queues.
Grab one, stack ‘em, and let it spark your next project. What’s yours? Drop ideas in the comments—I will be building custom knowledge graphs building new Venn diagrams mapping Occult Science and Quantum Physics.
Thanks again to Grok for turning 40 minutes of video gold into this 3-minute read. Follow xAI for more AI wizardry. Originally inspired by Level1Techs’ review—go watch for the full unboxing glee.
Comparison: NVIDIA DGX Spark GB10 vs. Custom 1U Server ASUS AGU-12ST
This table compares the two systems as potential ultimate AI developer workstations. The DGX Spark GB10 is a compact, purpose-built AI system launched on October 15, 2025, optimized for local AI development with NVIDIA’s full software stack. The custom server is a rackmount 1U build focused on general-purpose computing with added AI acceleration via a single GPU. Key metrics include AI horsepower (measured in peak tensor performance for relevance to AI workloads, using FP8 where available for consistency; note DGX uses sparse FP4, which is optimized for inference but not directly comparable—DGX vastly outperforms here), cost (CAPEX as one-time purchase), and power (OPEX as estimated max draw under AI load). Suitability is assessed qualitatively based on form factor, optimization, and developer workflow fit.
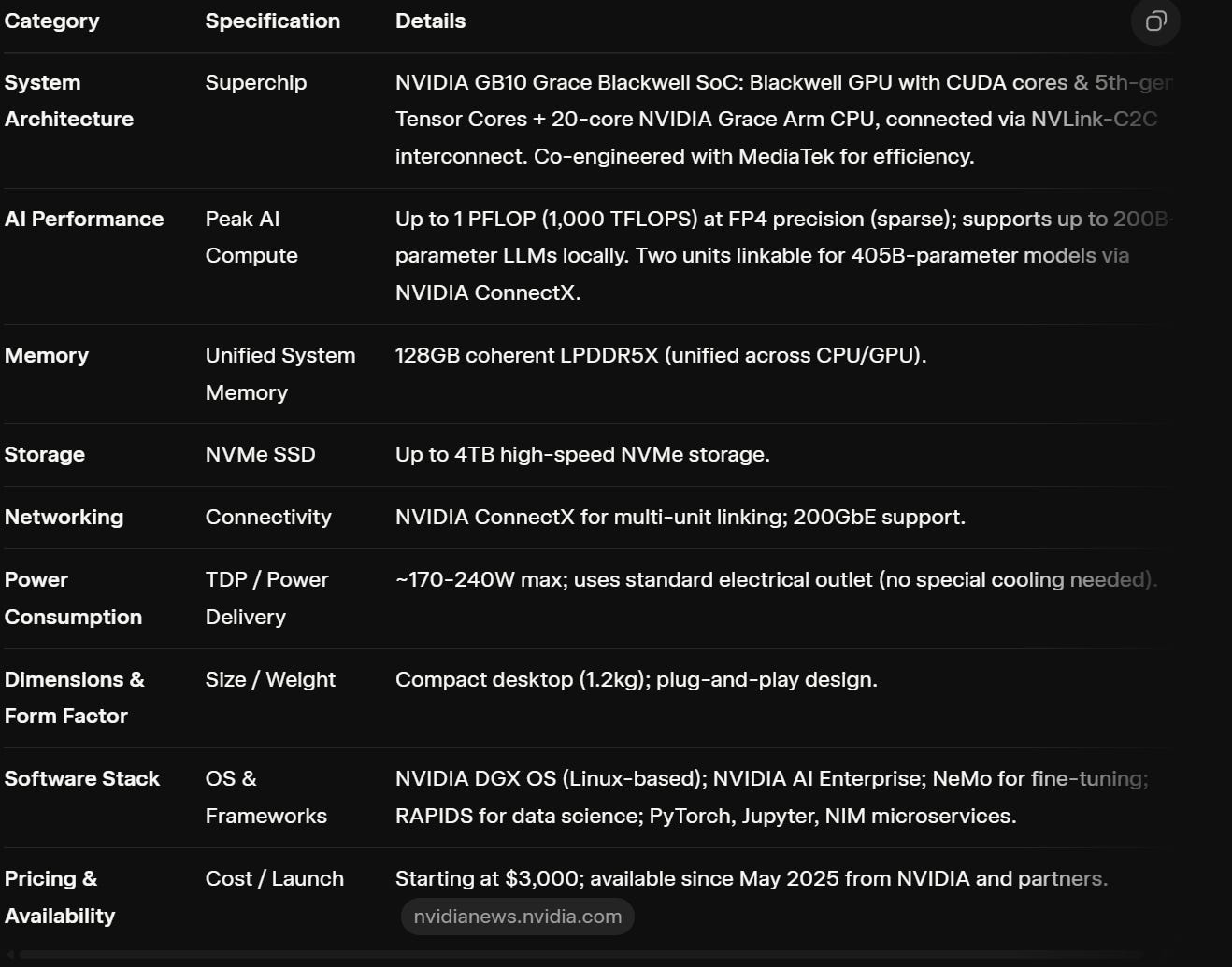


Excellent analysis, really apreciate the breakdown of the DGX Spark. That 230W powre brick for a petaflop of FP4 is truly impressive for local AI development, and your point about the complete Nvidia software stack changes everything.